
- About
- Events
- Notes and studies
- Bahā’ī studies
- Course syllabi
- Introductory/survey courses

- Higher-level courses
- Religion and society in the Middle East
- Nineteenth- and Twentieth-Century Iran
- Early Islamic history, 600–1258
- Arab-Israeli conflict
- Political Islam
- The Making of the modern Middle East
- History and development of Israeli society
- Minorities of the Middle East
- Shīʿī Islam
- History of Zionism
- Jews and Christians under Islam
- Jews of the Ottoman Empire
- The Middle East through film
- Israeli society through film
- Ottomans and Ṣafavids
- Israeli politics
- Mediæval Indian history
- Seminar/graduate courses
- Introductory/survey courses
- Publications
- News
- Contact
Transliteration tables
|
|
|
|

Table of contents
Arabic transliteration
For transliteration of Arabic (known in Arabic as ʿarabiyyah), I have chosen to conform to the basics of the system used in the International Journal of Middle East Studies (IJMES) [ ![]() ], the new Encyclopædia of Islam, 3rd ed. (EI3), and the Library of Congress (LOC) [
], the new Encyclopædia of Islam, 3rd ed. (EI3), and the Library of Congress (LOC) [ ![]() ], with two major exceptions: I always mark the tāʾ marbūṭah (ة) with an ‘h’ and I assimilate the definite article (al-/-ال) into the sun letters, both stemming from an effort to make the transliterations approximate both orthography and pronunciation.
], with two major exceptions: I always mark the tāʾ marbūṭah (ة) with an ‘h’ and I assimilate the definite article (al-/-ال) into the sun letters, both stemming from an effort to make the transliterations approximate both orthography and pronunciation.

Persian transliteration
Since Modern Persian (known in Persian as fārsī) is written using the Arabic alphabet, transliteration of Persian resembles very closely that of Arabic. Although a number of academic references tend to use an identical transliteration system for Persian and Arabic, I prefer to use a system similar to that of the Encyclopædia Iranica (EIr), with the minor difference of using consonantal digraphs. A major difference between the EIr system and the ‘Arabic-centric’ ones is that the short vowels are marked as they are pronounced in Persian (the Arabic ‘i’ and ‘u’ are the Persian ‘e’ and ‘o’). Hence, rather than write the name of the Iranian leader as ‘Khumaynī’, as an Arabic-reader would read it, I write ‘Khomeynī’; the spelling of Persian individuals bearing Arabic names follows this pattern (e.g., ʿAżod od-Dowleh, not ʿAḍud ad-Dawlah). With a few exceptions, I write Middle Persian words and names as they appear in modern Persian (e.g., Pīrūz, not Pērōz).

Hebrew transliteration
For transliteration of Hebrew (known in Hebrew as ʿivrīt), I have adopted a method, essentially that of the Society of Biblical Literature (SBL) [ ![]() ] and similar to that of the Jewish Quarterly Review (JQR) [
] and similar to that of the Jewish Quarterly Review (JQR) [ ![]() ], which highlights its shared elements with other Semitic languages. One difference from the SBL is that I transliterate the final héh (ה-), which marks the vowel ā, in order to represent the orthography. Unlike with Arabic, I do not mark doubled letters caused by the assimilation of the definite article (ha-/-ה) into sun letters; since the assimilation is neither pronounced nor visually apparent in Hebrew, transliterating it as such may prove confusing (thus, ha-kohén and not hak-kohén). The same goes for a number of the fricatives that are no longer in use (e.g., /th/ [תּ/ת], /dh/ [דּ/ד]). Because transliteration of Hebrew vowels is complex and often unnecessary, I do not usually mark them with macrons or other symbols.
], which highlights its shared elements with other Semitic languages. One difference from the SBL is that I transliterate the final héh (ה-), which marks the vowel ā, in order to represent the orthography. Unlike with Arabic, I do not mark doubled letters caused by the assimilation of the definite article (ha-/-ה) into sun letters; since the assimilation is neither pronounced nor visually apparent in Hebrew, transliterating it as such may prove confusing (thus, ha-kohén and not hak-kohén). The same goes for a number of the fricatives that are no longer in use (e.g., /th/ [תּ/ת], /dh/ [דּ/ד]). Because transliteration of Hebrew vowels is complex and often unnecessary, I do not usually mark them with macrons or other symbols.
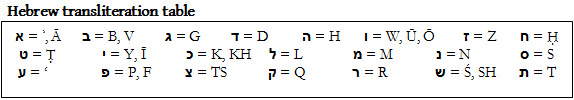

Related links
Image credits
- The Hebrew and Arabic alphabets along with respective transliterations into the Latin alphabet. Source: D Gershon Lewental (DGLnotes).